

大侦探福尔摩斯接到一张奇怪的字条:"我们约会吧! 3485djDkxh4hhGE 2984akDfkkkkggEdsb s&hgsfdk d&Hyscvnm"。大侦探很快就明白了,字条上奇怪的乱码实际上就是约会的时间"星期四 14:04",因为前面两字符串中第1对相同的大写英文字母(大小写有区分)是第4个字母'D',代表星期四;第2对相同的字符是'E',那是第5个英文字母,代表一天里的第14个钟头(于是一天的0点到23点由数字0到9、以及大写字母A到N表示);后面两字符串第1对相同的英文字母's'出现在第4个位置(从0开始计数)上,代表第4分钟。现给定两对字符串,请帮助福尔摩斯解码得到约会的时间。
输入格式:
输入在4行中分别给出4个非空、不包含空格、且长度不超过60的字符串。
输出格式:
在一行中输出约会的时间,格式为"DAY HH:MM",其中"DAY"是某星期的3字符缩写,即MON表示星期一,TUE表示星期二,WED表示星期三,THU表示星期四,FRI表示星期五,SAT表示星期六,SUN表示星期日。题目输入保证每个测试存在唯一解。
输入样例:
3485djDkxh4hhGE 2984akDfkkkkggEdsb s&hgsfdk d&Hyscvnm
输出样例:
THU 14:04
首先试一下char型的A、a、Z、z在C++中转换为int型的值:
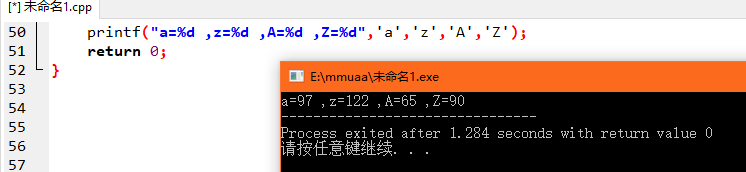
好吧不是挨着的,只能分情况考虑了。我个人比较习惯使用C++的string,使用迭代器访问元素,当然用char数组也不失是一种更为简便的方法。代码如下:
#include <cstdio>
#include <string>
#include <iostream>
using namespace std;
int min(int a, int b){
return a > b ? b : a;
}
int main(){
string a, b, c, d;
char s_1 = 'Z', s_2 = 'Z';
int s_3;
cin>>a>>b>>c>>d;
string::iterator a_it = a.begin(), b_it = b.begin();
for(int i = 0; i < min(a.size() , b.size()); i++){
if( *(a_it + i) == *(b_it + i) ){
if(s_1 == 'Z'){
if( (*(a_it + i) >= 'A') && (*(a_it + i) <= 'G') )
s_1 = *(a_it + i);
}
else if( (s_1 != 'Z') && ( ((*(a_it + i) >= 'A') && (*(a_it + i) <= 'N')) || ((*(a_it + i) >= '0') && (*(a_it + i) <= '9')) )){
s_2 = *(a_it + i);
break;
}
}
}
string::iterator c_it = c.begin(), d_it = d.begin();
for(int i = 0; i < min(c.size() , d.size()); i++){
if( (*(c_it + i) == *(d_it + i)) && ( ((*(c_it + i) >= 'A') && *(c_it + i) <= 'Z' ) || ((*(c_it + i) >= 'a') && *(c_it + i) <= 'z' ) ) ){
s_3 = i;
break;
}
}
switch(s_1){
case 'A':printf("MON ");break;
case 'B':printf("TUE ");break;
case 'C':printf("WED ");break;
case 'D':printf("THU ");break;
case 'E':printf("FRI ");break;
case 'F':printf("SAT ");break;
case 'G':printf("SUN ");break;
default:printf("GUN ");break;
}
if( s_2 <= '9' )printf("0%c:", s_2);
else{
printf("%02d:", (int)s_2 - 55);
}
printf("%02d", s_3);
return 0;
}